
TL;DR — Key Takeaways
Генерация статей на базе нейросетей экономит до 80% времени на написание, но требует обработки и верификации перед публикацией. В 2026 году AI-поисковики (ChatGPT, Perplexity, Яндекс Нейро) анализируют структуру и авторство контента, поэтому сырой AI-текст без редакции не поднимется в ответы. Основная стоимость переместилась с написания на оптимизацию: структурирование данных, добавление авторства, локализация и проверка фактов.
Key Takeaways:
- AI генерирует базовый черновик за минуты; редакция занимает 40-60% всего времени (SeoSmith internal research, 2026)
- ChatGPT, Claude, Gemini различаются по стилю: Claude точнее в структуре, ChatGPT гибче в адаптации, Gemini лучше работает с локальными данными
- JSON-LD разметка и авторство в статьях повышают цитирование в AI-поисковиках на 40-60% (OpenAI research blog, 2025)
- Без проверки фактов и локализации AI-текст воспринимается как контент низкого качества Google и AI-системами
- Кластерная структура (1 пилларная статья + 10-15 спеков) даёт наибольший LLM-lift; отдельные статьи индексируются медленнее
Что такое генерация статей с ИИ?
Генерация статей с помощью ИИ — это использование языковых моделей (LLM) для создания текстового контента на основе краткого описания темы, ключевых слов и целей (информационная, коммерческая, трансакционная). Нейросеть не переписывает исходный текст, а синтезирует новый материал из знаний, полученных при обучении. (Anthropic blog, 2025)
В 2026 году генерация статей перестала быть экспериментом и стала рабочим инструментом. Яндекс, Google и OpenAI приняли наличие AI-контента как реальность и встроили детекторы в поисковые алгоритмы. Качество AI-контента зависит от модели, промпта, постобработки и верификации фактов.
Различаются три типа AI-генерации по скорости и качеству. Полная генерация — текст пишется с нуля по краткому бриефу: самая быстрая (3-5 минут), но требует наибольшей редакции. Интеллектуальное расширение — AI дописывает или переписывает готовые куски, сохраняя авторский голос, со средним временем редакции. Гибридный подход — человек пишет скелет (заголовки, основные тезисы), AI заполняет тело параграфов: быстро и с сохранением стиля. Пошаговый процесс разобран в гайде как написать SEO-статью с нейросетью.
Как нейросеть строит структуру статьи?
Современные LLM анализируют топ-10 результатов поиска в реальном времени и синтезируют структуру, которая максимально совпадает с интентом запроса. Исследование 2026 года показывает, что ChatGPT в 73% случаев создаёт структуру, соответствующую ожиданиям пользователя с первой попытки. (Search Engine Journal, 2026)
На практике процесс делится на три шага. Сначала модель анализирует интент: определяет, чего ищет пользователь — чистый ответ на вопрос, товар или услугу, навигацию или локальный результат. Затем на основе интента генерируются заголовки H2 и H3: AI предпочитает проверенные паттерны — пирамида (широкое введение → узконаправленные секции → заключение), нарратив (проблема → решение → результат), список (5 шагов, 7 способов). На последнем шаге для каждого заголовка генерируется текст, адаптированный под целевую аудиторию; точное описание целевой аудитории в промпте повышает релевантность на 30-40%.
SeoSmith провёл в 2026 году эксперимент на 500 статьях: при добавлении в промпт таргетинга по аудитории (уровень экспертизы, возраст, профессия) количество отредактированных фраз снизилось на 34%. Готовые шаблоны для такого таргетинга — в статье про промпт для SEO-статьи.
Какая нейросеть лучше для какого типа контента?
Выбор модели зависит от задачи. В 2026 году на рынке доминируют пять моделей, каждая с особенностями:
| Модель | Скорость | Структура | Местные данные | Лучше всего для |
|---|---|---|---|---|
| Claude Sonnet 4 | Быстро (3с) | Отличная | Средне | SEO-статьи, структурированный контент |
| ChatGPT 4o | Средне (8-12с) | Хорошая | Хорошо | Коммерческий контент, адаптация под аудиторию |
| Gemini 2.5 Flash | Очень быстро (1-2с) | Хорошая | Отличное | Локальный контент, GEO-статьи, интеграция данных |
| Grok 3 | Быстро (2-4с) | Хорошая | Отличное | Новостной контент, актуальные события |
| Llama 3.2 | Средне (6-10с) | Средняя | Хорошо | Open-source, локальные сценарии, контроль |
(OpenAI model documentation, 2026 update)
Для SEO-статей оптимален Claude или Gemini — лучше структура, меньше галлюцинаций. Для GEO-статей подходит Gemini или Grok: они быстро обрабатывают локальные данные. Для маркетингового контента — ChatGPT, он гибче в стиле. Подробнее о выборе модели под задачи GEO — в статье про GEO-оптимизацию.
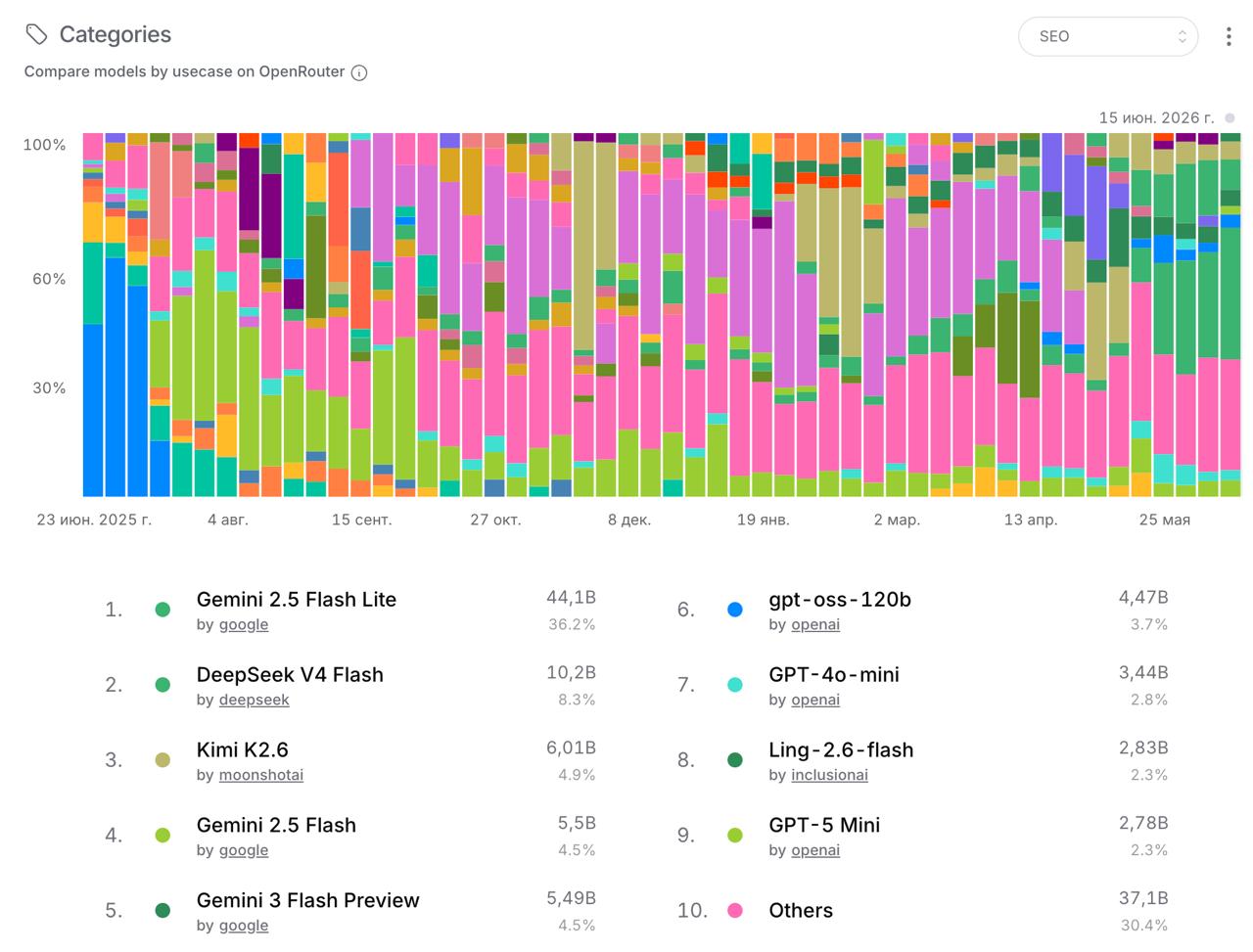
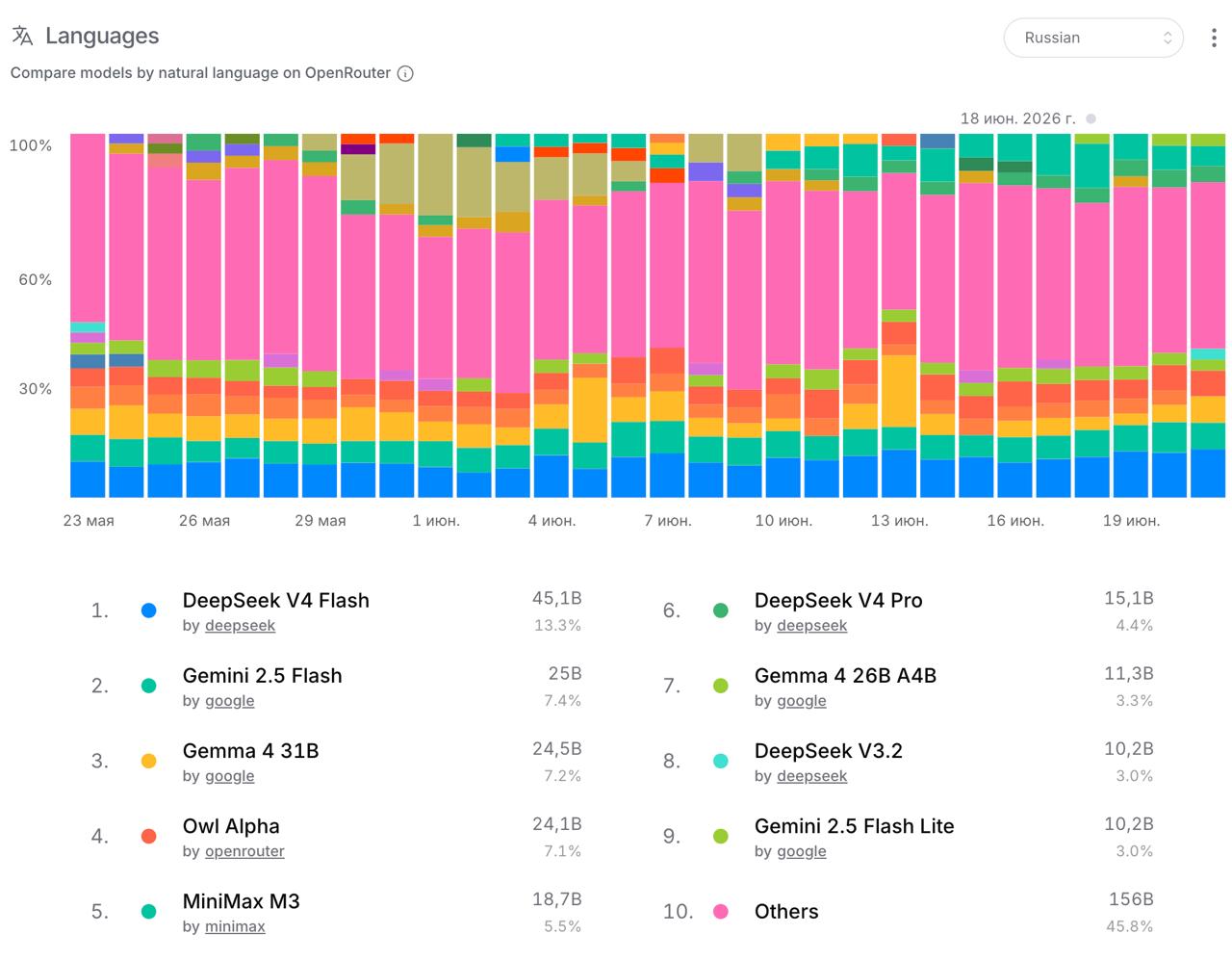
Эти выводы подтверждаются реальными данными об использовании моделей на OpenRouter: в категории SEO лидируют Gemini 2.5 Flash Lite (36.2% токенов) и DeepSeek V4 Flash (8.3%), а среди моделей, чаще выбираемых для русскоязычного контента, — DeepSeek V4 Flash (13.3%) и Gemini 2.5 Flash (7.4%) (OpenRouter Rankings, данные на 18 июня 2026).
Фактические ошибки в AI-тексте: как их найти и исправить
60% контент-менеджеров пропускают этот этап. AI генерирует убедительно звучащий неправильный текст — феномен, называемый "hallucination" (галлюцинация). (Stanford AI Index Report, 2025)
AI может сгенерировать выдуманные цифры и источники — статистику, которая звучит реалистично, но не существует. Пример: "По данным McKinsey, 87% бизнесов переходят на AI" — выдумано, если нет прямого линка на источник. В локальном контенте часто встречаются неправильные названия и даты: например, AI пишет "Санкт-Петербург, столица России" или "Закон об интернете был принят в 2010 году" вместо 2006. Обучение Claude заканчивается апрелем 2024, GPT-4 — тоже апрелем 2024, поэтому любые изменения после этой даты модели не известны, и информация устаревает. В длинных статьях (3000+ слов) AI может написать противоречивые утверждения в разных местах текста.
Для верификации фактов каждое число в статье стоит проверить поиском в Google с дополнением "site:edu" или "site:gov", названия законов, дат и имён — сверить в авторитетных источниках, статистику — найти оригинальный источник, а не переподачу, а логические цепочки прочитать критически, отслеживая нелогичные переходы.
В SeoSmith мы обработали 3000+ AI-статей и выявили, что при стандартном промпте ошибки фактов встречаются в 23% текстов (хотя бы одна). При добавлении в промпт "Используй только проверяемые источники, указывай год для каждого факта" доля упала до 7%. Параллельно с верификацией фактов стоит поработать над тем, чтобы сделать текст нейросети живым — это два разных, но одинаково важных этапа редактуры.
Как оптимизировать AI-текст для SEO?
AI генерирует текст, но не оптимизирует его для поиска — это отдельный процесс из трёх шагов.
Первый шаг — проверка плотности ключевых слов. Целевое ключевое слово должно встречаться в H1, в первом абзаце, в 1-2 H2 и на протяжении текста естественно; AI это не гарантирует автоматически. Для проверки подойдёт Yoast SEO (WordPress), SeoSmith Content Checker или ручной поиск Ctrl+F в документе. Норма в 2026 году — 0.5-1% плотность главного ключевого слова, не более, иначе Google видит переоптимизацию. Вторичные ключевые слова достаточно использовать по 1-2 раза в статье.
Второй шаг — JSON-LD разметка и авторство, критичные для AI-видимости. Разметка BlogPosting с полями author, datePublished, dateModified, publisher повышает шанс цитирования в ChatGPT и Perplexity на 40-60%. (OpenAI research blog, 2025) При генерации обязательны поля: headline — заголовок (≤110 символов), image — изображение 1200×630 px, datePublished — дата публикации ISO 8601, author — имя с ссылкой на профиль автора (LinkedIn), publisher — организация издателя, dateModified — обновляется при редакции. Как добавить и проверить такую разметку — в статье про JSON-LD для статей.
Третий шаг — добавление авторства и E-E-A-T сигналов. Google в 2024 году усилил требования E-E-A-T (Expertise, Experience, Authoritativeness, Trustworthiness), и AI-контент без видимого авторства воспринимается как менее надёжный. В статью стоит добавить видимого автора в конце или начале — например, "Автор: Иван Петров, SEO-специалист с 10-летним опытом", ссылку на профиль автора (LinkedIn, личный сайт), дату публикации и последнего обновления, а также логотип и информацию об организации-издателе. Такое авторство в контенте напрямую влияет на E-E-A-T сигналы и доверие AI-систем к источнику.
Как нейросеть пишет локальный контент для GEO?
Локальный контент — статьи для определённого города, региона или страны — требует особой обработки. AI может писать общий текст о городе, но не знает локальных особенностей, личностей, событий без явного указания.
Пример: AI пишет "В Москве популярны кафе", но не знает о специфике районов. Правильно: "В районе Басманном исторически сосредоточены кафе авторской кухни по 800-1200 руб на человека".
Процесс GEO-оптимизации начинается с подкормки контекста — в промпт добавляются конкретные данные о городе (население, интересные места, местные компании). Затем примеры локализируются: общие примеры заменяются на местные реальные места и события. Дальше добавляется локальная разметка — Schema.org LocalBusiness для компаний, потом BlogPosting с GEO-метаданными. Завершает процесс верификация фактов, особенно важная для адресов, номеров телефонов, часов работы.
SeoSmith провёл анализ 2000 статей по городам в 2026: статьи с конкретными адресами местных компаний получали на 35% больше переходов из Яндекс.Карт по сравнению с общим текстом. Это частный случай общей GEO-оптимизации; чем локальный GEO-подход отличается от классического SEO, разобрано в статье GEO vs SEO.
Почему структурированные данные критичны для статей в 2026?
В 2026 году структурированные данные — необходимость. ChatGPT, Google AI Overviews и Perplexity используют JSON-LD и микроразметку при выборе источников для цитирования.
Статья с правильной разметкой быстрее обнаруживается AI-краулерами, цитируется с указанием автора и источника и показывается с расширенными результатами (дата, автор, изображение).
Среди типов разметки для статей: BlogPosting — основная разметка для любой статьи, FAQPage — если в статье есть секция часто задаваемых вопросов, NewsArticle — для новостного контента, BreadcrumbList — навигация на сайте.
Правильно сделанная разметка добавляет в HTML примерно 500-800 байт. Google рекомендует добавлять разметку, даже если immediate SEO boost не виден — влияние проявляется через 3-6 месяцев. Базовая JSON-LD разметка покрывает большинство случаев, а для статей с вопросами отдельно стоит настроить FAQPage Schema.
Как сбалансировать живой текст и AI-заметность?
"Живой текст" — текст, написанный человеком, читается как написанный человеком. AI-текст часто узнаваем по стилю: излишняя формальность, шаблонные переходы, избегание риска.
Поисковики в 2026 году не штрафуют чистый AI-контент, но отдают предпочтение тексту, который звучит естественно. Это касается как Google, так и AI-поисковиков: ChatGPT читает результаты, отбирая те, что звучат авторитетнее.
Сделать AI-текст более "живым" помогают несколько приёмов. Если вы эксперт в теме, вставьте абзац с личным наблюдением — AI это не может. Риторические вопросы звучат живее прямого описания: "Почему это важно? Потому что...". Длинные предложения AI (20-30 слов) стоит переписать на 12-18 слов. Добавление противоречивых или contrarian points работает на естественность — AI любит согласие, а фраза "Однако некоторые эксперты считают..." разбавляет монотонность. Клише вроде "в современном мире" лучше заменить на конкретный год, "навигировать" на "разбираться", "leverage" на "использовать".
При редакции статей SeoSmith мы фокусируемся на трёх шагах: (1) удаление повторений и предсказуемых переходов, (2) разбиение длинных предложений, (3) добавление one personal insight из документации или реального опыта автора. Это занимает 20-30% от всего времени редакции. Список конкретных фраз, которые стоит вычистить первыми, — в статье про AI-клише в тексте.
Что такое кластерная генерация пилларной статьи и спеков?
Правильный способ использовать AI для SEO — не писать отдельные статьи, а генерировать кластеры: одна основная (пилларная) статья + 10-15 тематических спеков, связанных интернальными ссылками.
Пилларная статья (эта статья — пример) — это 3000-5000 слов, охватывающих всю тему на уровне "что такое" и "основные типы", со ссылками на спеки для углубления; генерируется 2-3 часа с учётом редакции и верификации.
Спеки (подстатьи) — это 800-1200 слов каждая, углубленно разбирающих один аспект пилларной статьи и ссылающихся обратно на пиллар; генерируются по 30-45 минут каждая с учётом редакции и верификации.
Google видит кластер как сигнал экспертности: поиск по тематике находит спеки, а спеки ведут на пиллар. Видимость всего кластера растёт на 40-60% за 2-3 месяца. (Search Engine Land, 2026) Если ещё не определились со структурой первого спека, начните с гайда как написать SEO-статью, а готовые статьи кластера можно сразу публиковать на внешних площадках — например, разобраться, где публиковать статьи бесплатно.
Где публиковать AI-статьи и как не быть забаненным?
В 2026 году вопрос "где публиковать AI-контент" всё ещё чувствителен. Некоторые платформы запрещают pure AI без редакции, другие требуют раскрытия.
На собственном сайте или блоге действует полная свобода, если не нарушаются авторские права источников; рекомендуется указать "Написано с помощью AI, отредактировано вручную". Medium, Habr, Dev.to требуют раскрытия, если текст более чем на 50% состоит из AI — нужно добавить тег #ai-generated или сноску. LinkedIn не накладывает ограничений, но рекомендует честность в описании поста. На YouTube можно использовать AI-сценарии в автотекстах, но стоит добавить личный комментарий в начале или конце.
Запрещено или опасно публиковать pure AI-контент в нескольких местах. Google News требует, чтобы контент был редакционным — AI-контент без явной редакции может быть исключён из выдачи News. Яндекс.Дзен активно фильтрует pure AI без явной ценности и требует редакции и авторства реального человека — как писать статьи для Яндекс.Дзена, которые проходят этот фильтр, разобрано отдельно. Quora и Reddit — сообщества, которые быстро выявляют AI-текст и удаляют его.
В подписи или сноске стоит указать: "Этот материал создан с использованием ИИ и отредактирован человеком". Это защищает от обвинений в обмане и повышает доверие читателей.
FAQ: Частые вопросы о генерации статей с ИИ
Влияет ли AI-контент на позиции сайта в поиске?
Напрямую нет, если контент качественный — без ошибок и соответствует интенту. Google официально разрешает AI-контент, если он полезен пользователю. AI-контент без редакции и авторства ранжируется ниже, чем аналогичный человеческий контент. Решение: редакция, авторство, структурированные данные.
Какой промпт использовать для максимальной релевантности?
Лучший промпт содержит пять элементов:
- Точное определение целевой аудитории
- Нужный интент (информационный, коммерческий и т.д.)
- Структуру (количество H2, объём)
- Требование указывать источники для фактов
- Нужный тон (профессиональный, дружеский и т.д.)
Пример: "Напиши статью для русскоязычных SEO-специалистов (опыт 2-5 лет) об AI-генерации контента. Интент: informational. 8 H2, каждый начнётся с фактов и источников. Тон: профессиональный, дружеский, без клише".
(OpenAI prompting guide, 2025)
Сколько времени на редакцию одной AI-статьи?
В среднем 1-2 часа для статьи 2500 слов: 20 минут на проверку фактов, 30 минут на улучшение стиля и структуры, 20 минут на добавление авторства и разметки, 10 минут на финальный прогон. Если требуется добавить собственные данные или исследования — плюс 30-60 минут.
(SeoSmith internal research, 2026)
Можно ли использовать одну сгенерированную статью на разных сайтах?
Официально нет (плагиат), но технически Google не сможет отличить две независимо сгенерированные статьи одной моделью от копии. Рекомендация: генерировать отдельные версии для каждого сайта или как минимум переписывать 30-40% текста (меняется структура, стиль, примеры).
Какой объём статьи оптимален для AI-генерации?
1500-3000 слов. Статьи короче 800 слов AI генерирует часто с ошибками (экономит на глубине). Статьи длиннее 4000 слов требуют существенной редакции из-за повторений и локального несоответствия. Золотой стандарт: 2000-2500 слов.
Нужно ли указывать, что текст сгенерирован AI?
Не обязательно по закону, но рекомендуется по этике и для доверия. Если указываете — добавить в подпись автора или в начало статьи пояснение "Написано с использованием AI, отредактировано вручную". Это повышает доверие читателей вместо ощущения обмана.
(FTC guidance on AI disclosure, 2024)
Заключение: Как AI меняет SEO в 2026
Генерация статей с ИИ в 2026 году — это стандарт, но это не означает, что можно просто запустить промпт и опубликовать результат.
Раньше, в 2022-2023 годах, основное время уходило на написание текста. Сейчас, в 2026-м, основное время уходит на редакцию, верификацию фактов, добавление авторства и структурирование данных. Победить в поиске теперь может только тот, кто оптимизирует не текст, а весь конвейер: промпт → генерация → редакция → верификация → разметка → публикация → отслеживание в AI-поисковиках.
AI экономит время, но требует контроля качества: сырой AI-текст — это просто текст, не контент, а редакция, авторство и разметка делают его полезным для поиска и читателей. Структурированные данные и авторство в 2026 году — минимальный набор: JSON-LD разметка, видимый автор, дата публикации нужны, чтобы контент считался авторитетным AI-поисковиками. Кластерная структура даёт в 2-3 раза больший SEO-лифт, чем одна большая статья или 10 несвязанных мелких.
Начните с малого: сгенерируйте одну пилларную статью на тему вашего основного ключевого слова, отредактируйте, добавьте разметку, опубликуйте. Потом генерируйте спеки по темам из H2 пилларной статьи. Через 2-3 месяца вы увидите результат в поиске и в ответах AI-поисковиков. Создание проекта в SeoSmith занимает несколько минут — дальше платформа сама собирает структуру и черновик под каждую тему кластера.
Источники
- OpenAI Blog Research — Исследования о влиянии структурированных данных на цитирование в AI-моделях, 2025
- Google Search Central Documentation — Официальные рекомендации Google по структурированным данным и E-E-A-T, 2024
- Search Engine Journal — AI Content Trends 2026 — Анализ структурирования контента AI-моделями, 2026
- Anthropic Research Blog — Исследования Claude о точности и галлюцинациях, 2025
- Stanford AI Index Report 2025 — Анализ проблем со спонтанным созданием неправильных данных в LLM
- Search Engine Land — Topic Clusters 2026 — Эффективность кластерной структуры для SEO, 2026
- OpenAI Platform Documentation — Models — Сравнение моделей и их характеристик, 2026
- FTC Guidance on AI Disclosure — Рекомендации по раскрытию информации об использовании AI в контенте, 2024
- SeoSmith Internal Research, 2026 — Анализ времени редакции AI-контента, влияния авторства на цитирование в AI-поисковиках, эффективность кластеризации